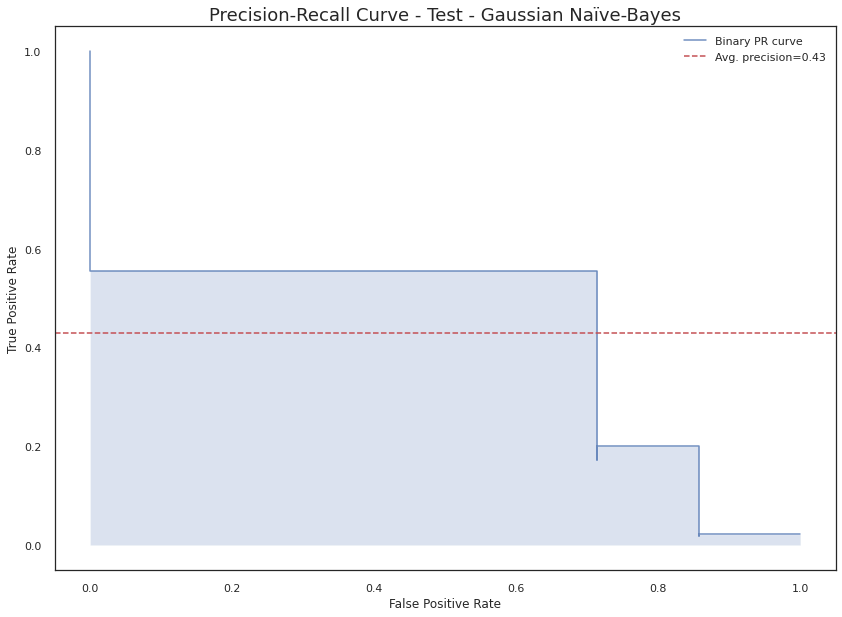
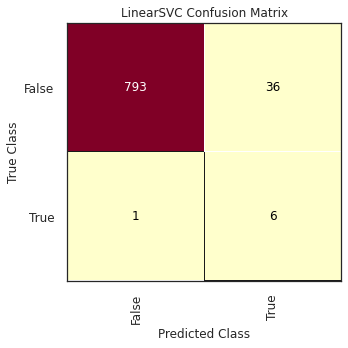
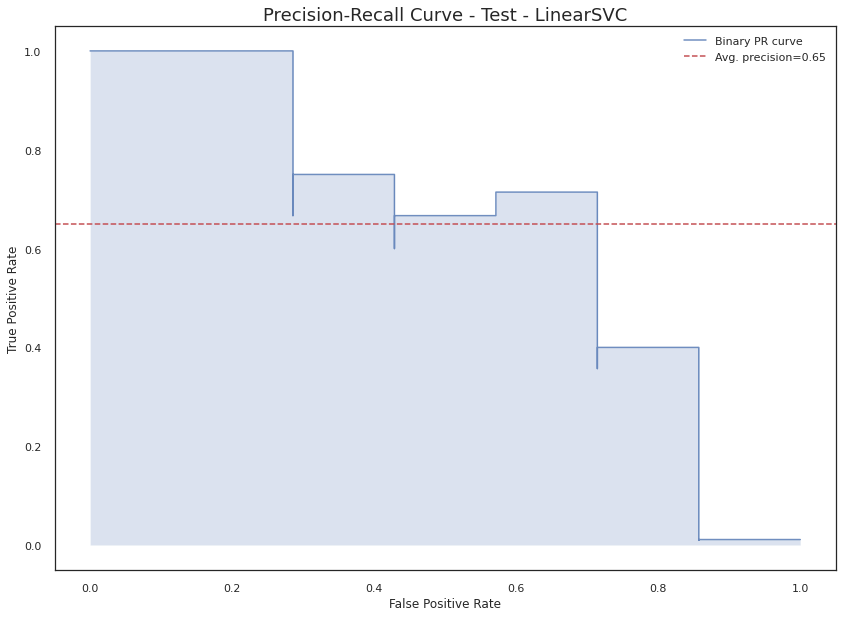
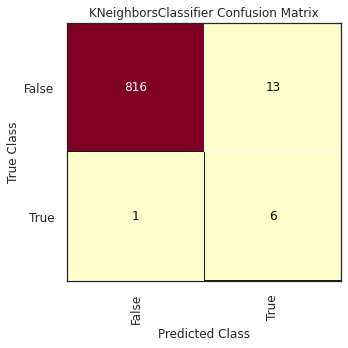
In this phase, the goal is to train several classification models and test their performance against our dataset. Then, after having the results using a set of evaluation metrics we will choose the best classifier. This whole process starts with the splitting of our initial dataset into three sets (Training, Test, and Validation), following the criteria we discussed at the Exploratory Data Analysis, and then apply the pre-processing step: the transformation and selection of features (over the Training and Test datasets) and also applying SMOTE to mitigate the effect of the imbalance of the classes.
# Import Git datasetdata_path ='./datasets'df_git = pd.read_json('{}/df_git.json'.format(data_path), orient='records', lines=True)# Separate target variabley_git = df_git.pop('author_bot')## Re-generate "Train", "Test" and "Validation" data sub-sets# Divide the Dataset into 60% training and 40% test + validationX_train_git_og, X_test_tmp_git,\y_train_git, y_test_tmp_git = train_test_split(df_git, y_git, test_size=0.4, random_state=22, stratify=y_git)# From 40% of the original dataset, 25% is for test and 15% is for validation# This means we have to split the test+validation set in a 62,5%/37,5% ratioX_test_git_og, X_val_git_og,\y_test_git, y_val_git = train_test_split(X_test_tmp_git, y_test_tmp_git, test_size=0.375, random_state=22, stratify=y_test_tmp_git)
Apply pre-processing to the training and test datasets
After performing the Exploratory Data Analysis, we have a clear process to consider which transformation apply to the variables and which are the ones we are selecting.
Apply SMOTE to mitigate the effect of imbalanced data
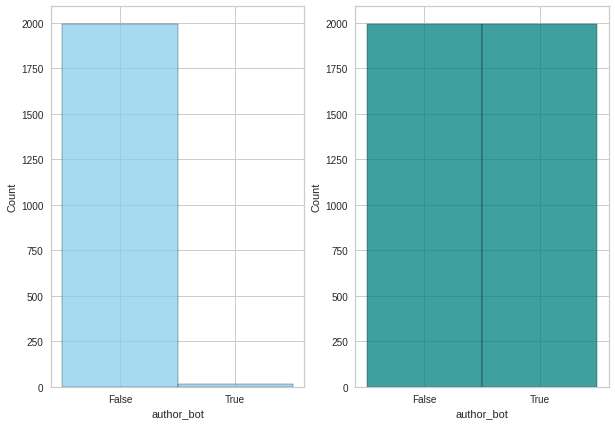
We already commented in the Exploratory Data Analysis the fact that one of the main challenges of this project is the imbalance in the target class we are aiming to detect. This context was taken into account when splitting the main dataset into the training, test, and validation tests, but it needs another processing stage before they feed the different classification models.
SMOTE is based on an algorithm generating new samples considering the k-nearest neighbors from each original sample from the training set. Each newly generated sample is interpolated between the original sample and one of the nearest neighbors; with a random component \(\lambda\), which takes value in the range \([0, 1]\).
We applied PCA (Principal Component Analysis} to discover if there was a combination of features that would suit as input for the classification model, but we discarded it as the results indicated that one component accumulated most of the percentage of variance explained.
Code
pca = PCA(n_components=3, random_state=22)principalComponents = pca.fit_transform(X_train_git_SMOTE)trainDf = pd.DataFrame(data=principalComponents)variance_ratio =list(pca.explained_variance_ratio_)count =0# in case list is emptyfor count, var inenumerate(variance_ratio, start=1):print('Var. {}: \tExplained Variance ratio: {}'.format(count,round(var, 3)))
Var. 1: Explained Variance ratio: 0.983
Var. 2: Explained Variance ratio: 0.011
Var. 3: Explained Variance ratio: 0.002
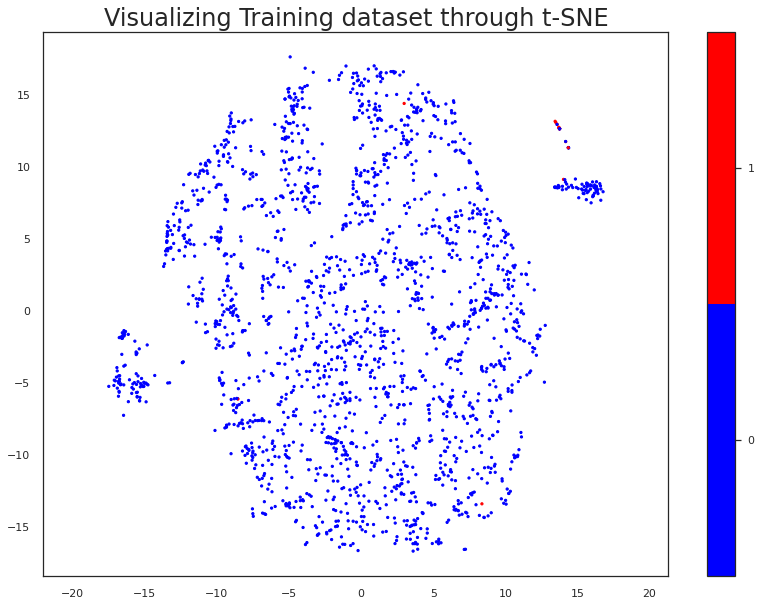
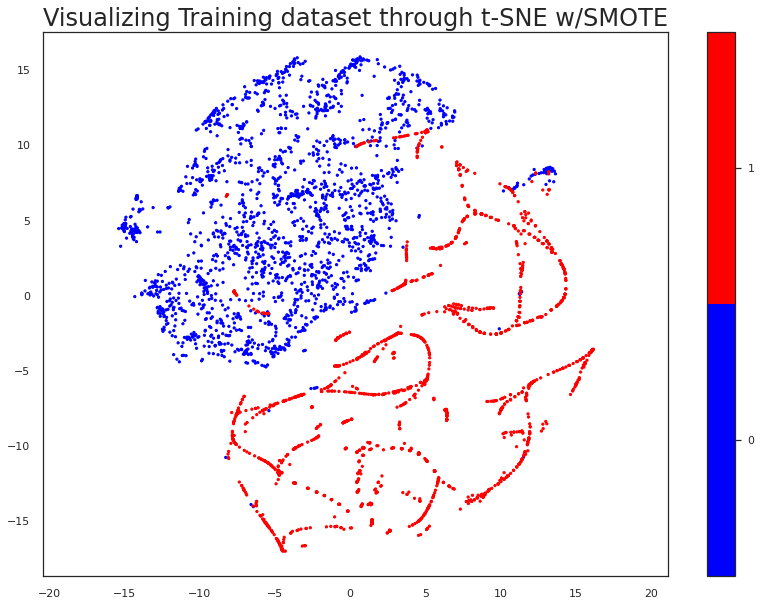
Study classes’ distribution using t-SNE
Here, the objective is to show how the samples from the Training set were distributed using the t-SNE algorithm, a nonlinear dimensionality reduction technique. This way we could convert our high-dimensional dataset into a two-dimensional one, preserving the distance between the samples in the new dimensional space.
The following figures show the redimensioned Training dataset before and applying SMOTE, respectively: In the first image, we can observe very few occurrences of positive bot accounts, and heavily mixed among the rest of the samples from the other class; while in the second image we can observe a much clearer distinction between the two classes, after the synthetic samples generated by SMOTE. Apart from the interesting pattern these samples are forming, we infer that there should be a classification model capable of separating both classes.
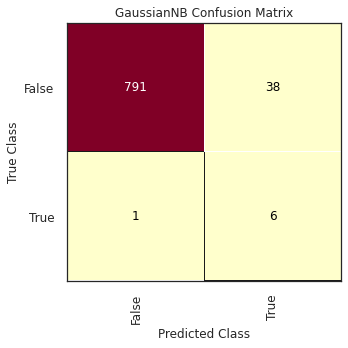
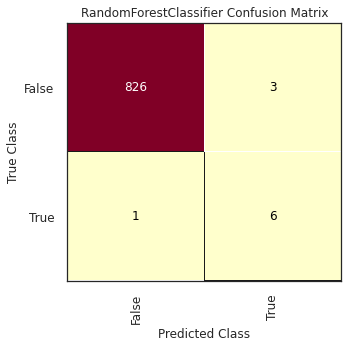
We need to use a set of metrics that help us to evaluate the performance of the different classification models. The main method to compare the results from the different models is a confusion matrix, which displays the number of elements that have and have not been identified correctly.
Looking at the possible values we can obtain, it is worth mentioning that not all the misclassified cases affect our use case in the same way: having False Negatives is worse than having False Positives. This means it is more important to classify as many bot accounts as possible (and not mistake any of them for a human) rather than classifying a human as a bot when it is not the case. In the first case, missing a bot account among the plethora of contributors in a community could mean that potentially this bot account remains hidden (and hardly going to be identified); while in the latter, this wrong recommendation could be just ignored.
This links directly to the definition of two basic metrics: precision and recall. As it is defined in Scikit-learn’s documentation page, an intuitive definition of precision is the ability of the classifier not to label as positive a sample that is negative, and recall is the ability of the classifier to find all the positive samples.
Although it is common to use the \(F_{1} score\) as an evaluation metric for classification models, this score is considering that the recall and the precision are equally important. This is why the decision was to use a \(F_{\beta}\) score with \(\beta = 2\), to penalize those classification models with a greater number of False Negatives.
The proposed classifiers were trained and then tested, adjusting the specific hyper-parameters for each model until finding the best scoring for each of them.
Gaussian Naïve-Bayes
Naïve-Bayes supervised-learning algorithms are based on Bayes’ theorem. They belong to the Probability-based learning family, and their approach is to use estimations of likelihoods to determine the most likely predictions that should be made and review them later, based on the available data and also extra evidence whenever it becomes available.
Naïve-Bayes classifiers are especially useful for problems with many input variables, categorical input variables with a vast number of possible values, and text classification. Among the advantages of using these classification models are their simplicity to apply (generally, no parameters to be adjusted) and their resistance to over-fitting.
The selected classifier was the Gaussian Naïve-Bayes algorithm
The support vector classifier is based on the possibility of constructing a hyperplane that separates the hyperplane training observations perfectly according to their class labels. Once this hyperplane exists, the ideal scenario is that a test observation is assigned to a class depending on which side of the hyperplane it is located.
Nonetheless, observations that belong to two classes are not necessarily separable by a hyperplane. In fact, even if a separating hyper- plane does exist, then there are instances in which a classifier based on a separating hyperplane might not be desirable. A classifier based on a separating hyperplane will necessarily perfectly classify all of the training observations; this can lead to sensitivity to individual observations and implies that it may have overfit the training data.
The support vector classifier does exactly this. Rather than seeking the largest possible margin so that every observation is not only on the correct side of the hyperplane but also on the correct side of the margin, we instead allow some observations to be on the incorrect side of the margin, or even the incorrect side of the hyperplane.
K-Nearest Neighbors is a similarity-based classification model whose main idea is to compute the classification from a simple majority vote of the nearest neighbors of each point: a query point is assigned the data class which has the most representatives within the nearest “k” (integer number) neighbors of the point.
Note that this algorithm uses the whole training dataset for making the predictions, and aside from other classification models, there are no specific assumptions that should be made concerning the data. One of the main setbacks is the fact that this algorithm is affected by noise, which implies this parameter “k” needs to be selected carefully, particularly when working with imbalanced datasets.
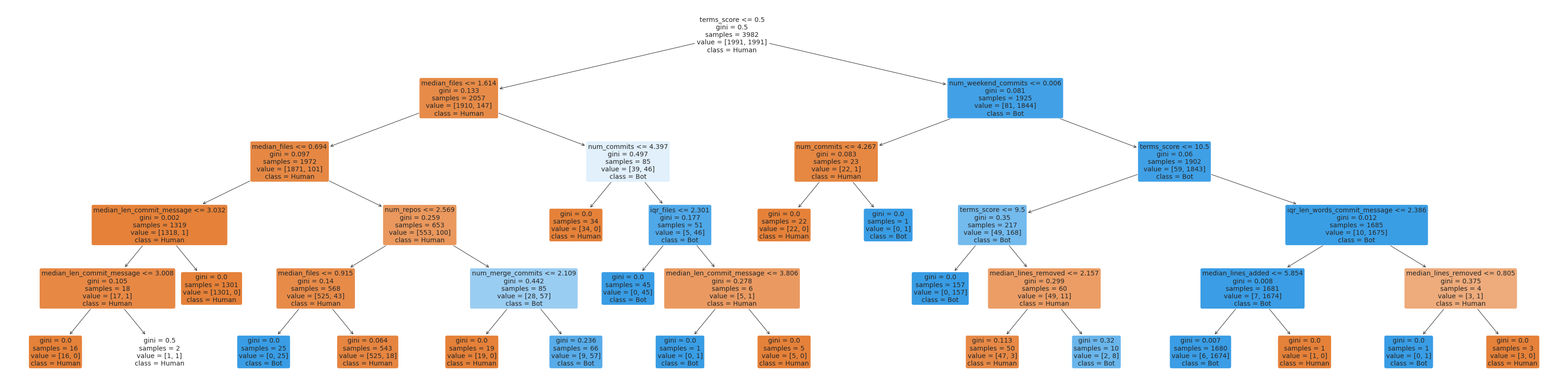
The Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. A tree can be seen as a set of if-else decision rules.
Providing a more academic definition, a classification tree predicts that each observation belongs to the most commonly occurring class of training observations in the region to which it belongs. In interpreting the results of a classification tree, we are often interested not only in the class prediction corresponding to a particular terminal node region, but also in the class proportions among the training observations that fall into that region.
We use recursive binary splitting to grow a classification tree. Since we plan to assign an observation in a given region to the most commonly occurring class of training observations in that region, the classification rror rate is simply the fraction of the training observations in that region that do not belong to the most common class. When building a classification tree, either the Gini index or the entropy is typically used to evaluate the quality of a particular split, since these two approaches are more sensitive to node purity than the classification error rate. Any of these three approaches might be used when pruning the tree, but the classification error rate is preferable if the prediction accuracy of the final pruned tree is the goal.
We have tested the Decision Trees algorithm. Let’s have a lookt at some of its pros and cons.
Some of the main advantages of this algorithm are:
It is simple to understand and interpret. Trees can be visualized: if a given situation is observable, the explanation for the condition is easily explained by boolean logic.
Requires little data preparation. Other techniques often require data normalization, dummy variables need to be created and blank values to be removed.
Performs well even if its assumptions are somewhat violated by the true model from which the data were generated.
The most remarkable disadvantages are:
DTs can create over-complex trees that do not generalize the data well (over-fitting).
They can be unstable because small variations in the data might result in a completely different tree being generated.
Decision-tree learners create biased trees if some classes dominate. In our case, this effect would be mitigated because we applied SMOTE to balance both classes.
Regarding the two first disadvantages, both can be addressed by using an ensemble model taking many decision trees. This is where the Random Forest (RF) classifier comes into play: it builds a number of decision trees on bootstrapped training samples. When building these decision trees, each time a split in a tree is considered, a random sample of \(m\) predictors is chosen as split candidates from the full set of \(p\) predictors. The split is allowed to use only one of those \(m\) predictors. A fresh sample of \(\sqrt{m}\) predictors is taken at each split, and typically we choose \(m \approx p\)—that is, the number of predictors considered at each split is approximately equal to the square root of the total number of predictors.
Then, the prediction of the ensemble is computed as the averaged prediction of these individual classifiers, improving the predictive accuracy and preventing over-fitting.
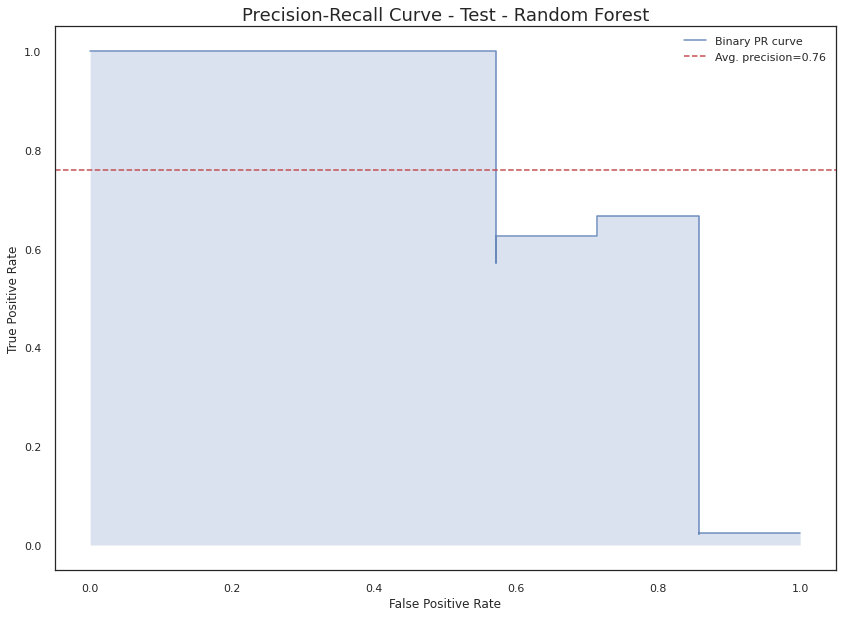
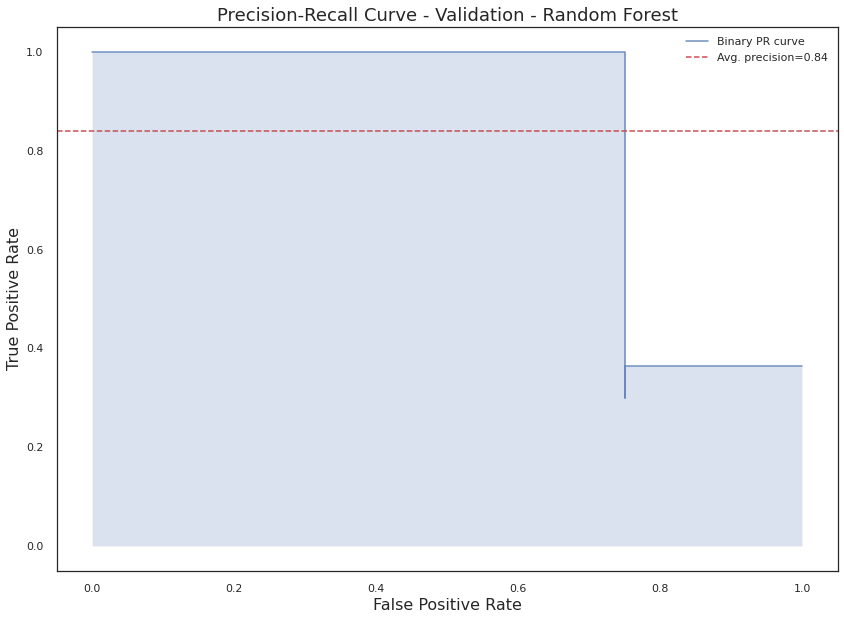
plt.figure()plt.title("Precision-Recall Curve - Test - Random Forest", fontsize=18)plt.xlabel("False Positive Rate", fontsize=12)plt.ylabel("True Positive Rate", fontsize=12)visualizer = PrecisionRecallCurve(rf_adj, classes=['Human', 'Bot'])visualizer.fit(X_train_git_SMOTE, y_train_git_SMOTE)visualizer.score(X_test_git, y_test_git)plt.legend();
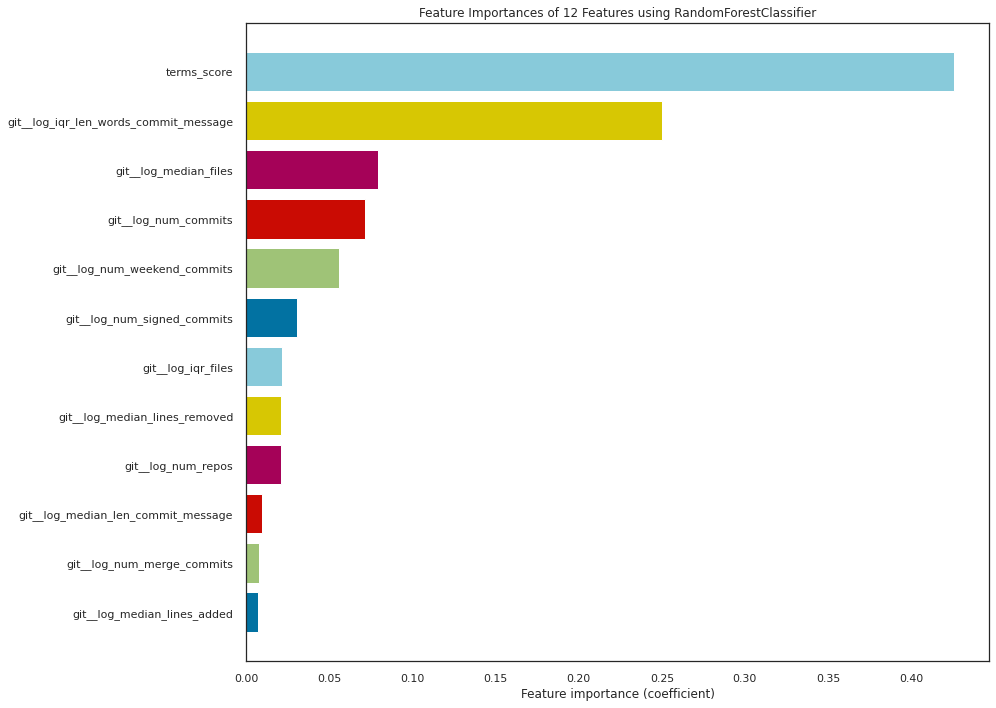
Feature importance
Code
viz = FeatureImportances(rf_adj, xlabel='Feature importance (coefficient)', relative=False, colormap='yellowbrick')viz.fit(X_test_git, y_test_git)viz.show();
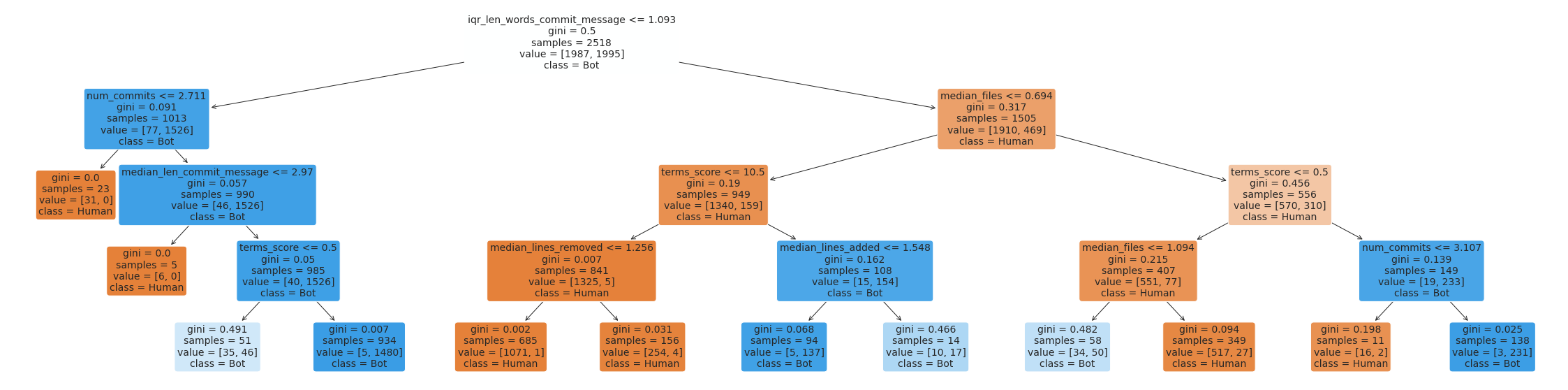
Plot some trees composing the random forest
Code
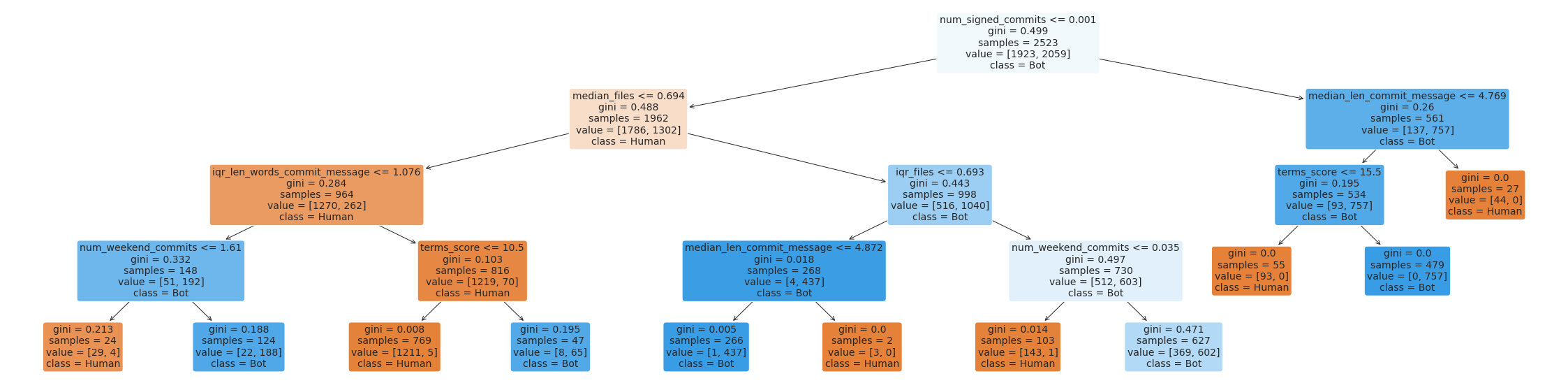
# Plot a couple of the trees composing the random forestplt.figure(figsize=(40,10))tree.plot_tree(rf_adj[22], feature_names=list_cols, class_names=['Human', 'Bot'], filled=True, rounded=True, fontsize=14)plt.show()
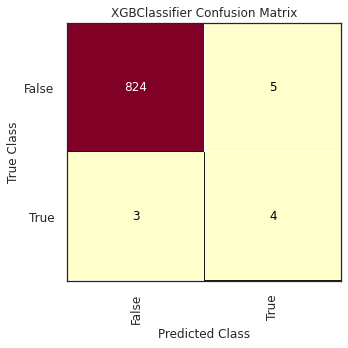
XGBoost is an ensemble model which uses decision trees as base learners. XGBoost uses CART trees (Classification and Regression trees), with scores on whether an observation belongs to a class or not. When this process reaches the max depth of the tree, the algorithm converts the scores into categories assigning a threshold value.
[22:52:48] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
Score
F2-score
0.541
Precision
0.444
Recall
0.571
Models Evaluation
The results from the tested classifiers are summarized in the following table:
Code
df_scores
model_subset
model_name
precision_score
recall_score
f2_score
0
Test
Gaussian Naive-Bayes
0.136
0.857
0.417
1
Test
LinearSVC
0.143
0.857
0.429
2
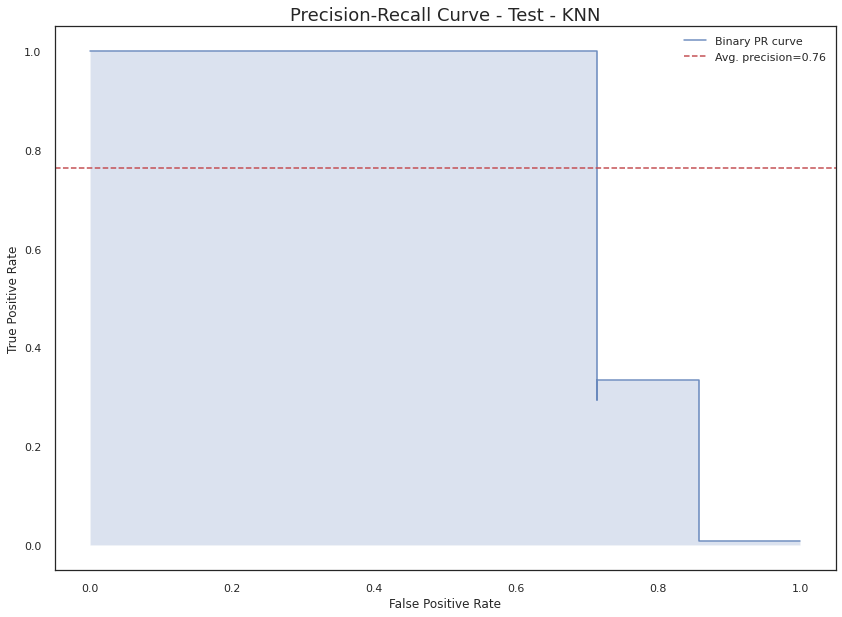
Test
KNN
0.316
0.857
0.638
3
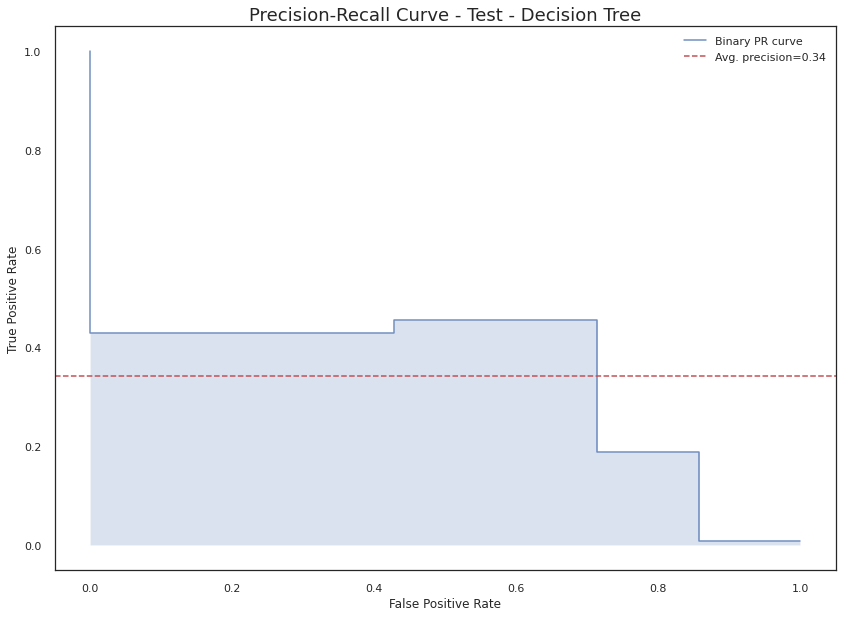
Test
Decision Tree
0.385
0.714
0.61
4
Test
Random Forest
0.667
0.857
0.811
5
Test
XGBoost
0.444
0.571
0.541
The classification model with the best results was the Random Forest Classifier. These results were also tested using a 5-fold cross validation.
The parameters that worked best for the Random Forest Classifier were:
Number of estimators (Trees in the forest): \(300\).
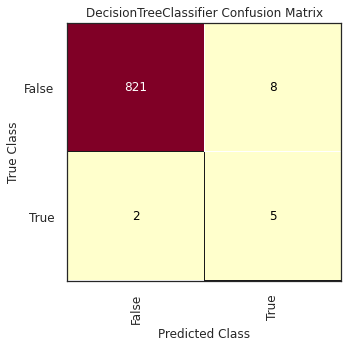
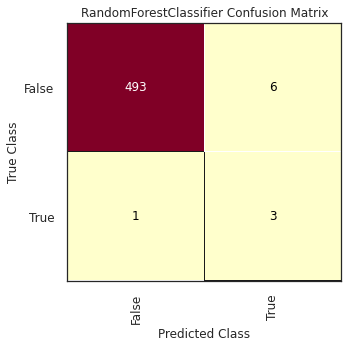
The classification model with the best results was the Random Forest Classifier, with \(F_{\beta} = 0.811\) using the Test dataset. According to the results, \(6\) out of \(7\) bot accounts were properly classified, and \(826\) human accounts out of \(829\).
Next step is to validate the chosen classifier with the Validation dataset.
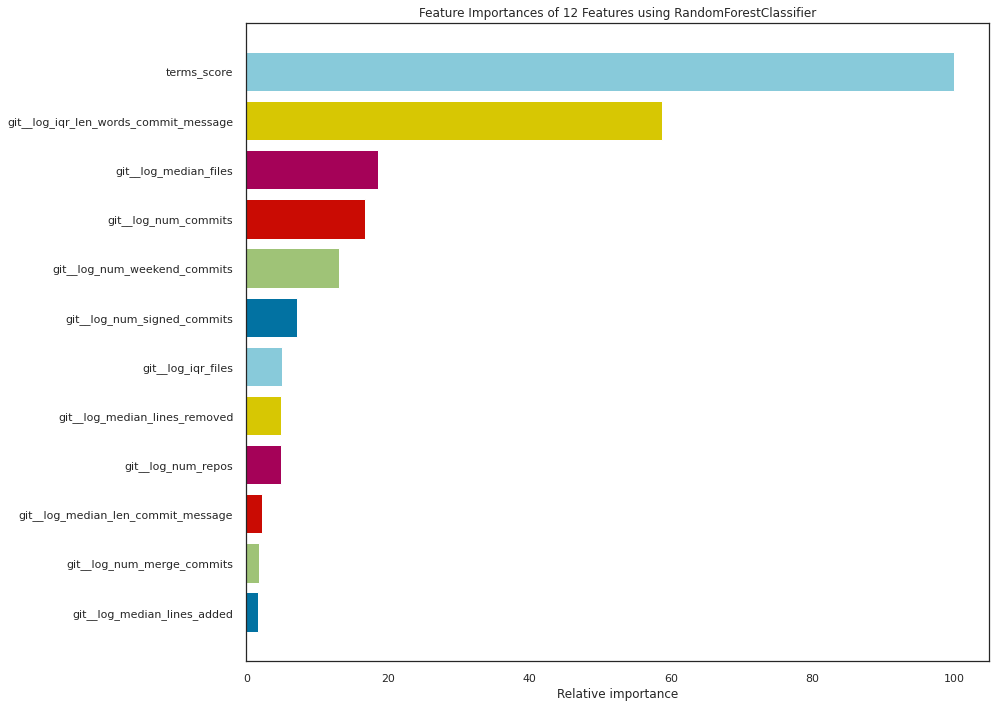
viz = FeatureImportances(rf_adj, xlabel='Relative importance', relative=True, colormap='yellowbrick')viz.fit(X_val_git, y_val_git)viz.show();
Conclusion
When trying these results with the Validation dataset, the obtained score was \(F_{\beta} = 0.6\). Given that there were only \(4\) occurrences of bot accounts, three of them were classified correctly and only one was not. Regarding the human accounts, \(493\) out of \(499\) accounts were classified accurately.
Looking at the feature importances obtained from our chosen classifier, it is clear that the terms score variable we produced was the most relevant for deciding the classes, followed by the logarithmic transformation of the interquartile range of the number of words in the commit messages, with a relative importance of \(60\%\). Then, the logarithmic transformation of the median number of files and the number of commits have a relative importance of around \(20\%\), while the rest of the variables are barely significant for the classification.